Last time we quickly ran through the method for cracking the cookies issued by an instance of PHP issuing outputs from mt_rand(). However, the method used was flawed. We can do better just by attacking the problem some more.
First, a basic optimisation to solve two problems at once. When running early attack code, I made the mistake of executing hashcat on a single SHA-1 hashed value at a time. During this research, I learned that doing so (especially in the case when you have a large group of values to crack) is akin to making a separate return trip to the shops for each individual item on a long grocery list. And the shop is on the other side of the planet – and you are travelling by foot. Quite inefficient, to say the least. Hashcat takes a good second or two just to prepare all of that GPU beef for the task of cracking and this overhead does not scale well on time or resources.
The second mistake I made was assuming that mt_rand() outputs are always either 9 or 10 digits long. Well, it turns out that this is not the case – it’s just biased towards those longer values, as there are naturally more 2 digit values than 1 digit values, just as there are more 3 digit values than 2 digit values, and so on. When testing manually I usually only saw 9 or 10 digits. Since automating my efforts, I’ve seen 4 and 5 digit outputs, and I don’t think there’s any theoretical barrier to getting single digit mt_rand() outputs.
The assumption led to failed cracking attempts, and the inefficiency made such failures take a long time. The answer to both is built in to hashcat: masks.
I wrote code to generate a hashcat mask file (plaintext with .hcmask extension):
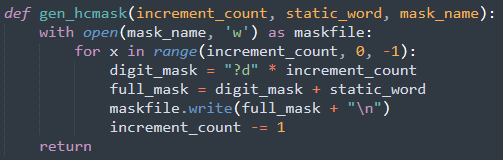
This code writes each mask (one per line) with a decrementing number of digits (from 10 to 1), followed by the known portions of plaintext. Hashcat starts at the top, exhausts the mask and then moves to the next if it didn’t crack everything in its input buffer. As we have statistical bias for longer values, this is optimised by decrementing as it goes after the most likely first, but also will cover every possible value eventually.
Referring to the previous post, the structure of the plaintext cookie is:
Now we deal with the other component: the timestamp. This is written to the cookie by the server, so that’s the clock that matters although yours may differ. Luckily, the server writes its time to every packet – but we do have to account for the occasional mismatch caused by the delay between the server getting a Unix timestamp when the second is just about to tick over, and then creating the TCP packet which will send it in encrypted form as a cookie, only to write the following second onto that packet’s timestamp because of the very small delay. As we supply this timestamp to hashcat as a “known” input and not something to fuzz with a mask, if you get the timestamp wrong you will not crack the hash. Enter server-time synchronisation!
It’s as cool as it is simple: You just send packets to the server as quickly as you can and note when the server’s time (written with 1 second resolution) ticks over to the next second. The moment that happens, you use Python’s time.perf_counter_ns() to grab the nanosecond portion from your own clock. That moment in time is roughly when the server’s millisecond value has reset to 0 in the new second it replied with. Now you know when a second is about to tick over on the server by comparing your current clock to that value, so you refrain from sending a request for maybe 80-100 milliseconds either side of that. If you have high latency to the server it may be more – try 3 or 4 times the latency, but just make sure to avoid the second-tickover barrier.
With this done, we now have an efficient way of cracking whatever mt_rand() output was in the plaintext cookie because we know what the timestamp will be, and we always know the static word appended to the end. Cracking proceeds without issue and you can easily extract your known word (“Impossible”) and the appropriate timestamp from the plaintext, leaving only the mt_rand() value. This happens orders of magnitude faster than before because we can now group all cookies by the timestamp they were generated with and execute hashcat far fewer times, far more efficiently each time.
The core problem still remains. We need to receive the first few values after a reseed event or PHP_mt_seed will slow to a crawl. Enter a technique which is almost too good to be true: the Two Value Attack.
Take the time to read the post, because I’m not going to pretend to fully understand what all of this bitshifting and XORing really does or why this works – it just does. You take any output which is within the first 394 after seeding, you then take the output exactly 227 positions after that one, supply both as inputs to the attack and it will give you the seed. Magic!
This attack is orders of magnitude faster than the brute force method from PHP_mt_seed. That’s fortunate because, as it turns out, these cookies probably won’t always be in perfect thread-order like:
…
4_11,
0_12 ,
1_12,
2_12,
3_12,
4_12,
0_13 …
Sometimes, a PHP thread will skip its turn and break the proper order of things by falling one behind. The more cookies you collect, the more this happens, the more disordered they get. Naturally, on a live server with other users making requests this will happen often.
We will have to be fuzzy with our attempts – taking the first value and trying the one at index + (thread count * 227) later, then (thread count * 228), then (thread count * 226) etc. But as the attack is so much more efficient it really doesn’t matter. I am thankful for such awesome code written by people smarter than me.
The last part of the real challenge was to jump into the output stream ANYWHERE – but the answer to that will have to wait for part III… In the meantime, some interesting reflections on what you can do if you successfully crack all the seeds for running PHP workers serving mt_rand() values.
Once you crack the seeds for all running threads, it becomes trivial to assign the outputs you collected to their proper stream, because you can predict them, after all, and collisions are rare in such an algorithm with only a few hundred outputs per thread. So, you can figure out which position each stream is at – take this as the state at one moment in time:
Thread 1: 304th output
Thread 2: 305th output
Thread 3: 304th output
Thread 4: 304th output
Thread 5: 303rd output
Well, you can then poll each thread by requesting N +1 cookies, where N is the number of threads. The +1 covers the occasional hiccup in the normal order of things. And something special happens if you poll like this once per second, or once per 5 seconds.
Say you suddenly receive an output which is 1 later in the output stream for that seed than you expected. One output is missing – because another user received it!
Because it was skipped, you know someone else has it in their cookie. Because you poll every second or 5 seconds, you know pretty much exactly when this happened. The third part of the plaintext cookie is static, so after cracking the known output with a small possible number of timestamps to go with it, not only do you know exactly when a user was issued a new cookie, but you can then immediately supply it to the server and figure out who it was by being logged in as them.
If you go with 1-second polling, you now have a realtime alerting and ATO system running on the website – if mt_rand() is in use for something other than cookie generation you will get some false positives, but you can hijack every session that happens after you run the above attack. Lucky nobody really uses this method to generate cookies!